原贴:
上一篇介绍了QUAD_COMMAND渲染命令,顺带介绍了VAO和VBO,这一篇介绍批处理渲染命令BatchCommand,批处理命令的处理在Render中比较简单
1 else if(commandType == RenderCommand::Type:: BATCH_COMMAND)2 {3 //将之前缓存的绘制4 flush();5 auto cmd = static_cast (command);6 //调用命令7 cmd->execute()8 } 首先调用flush将之前缓存的VBO绘制出来,然后调用命令自己的执行函数,这个过程和CUSTOM_COMMAND是一样的,不同的是这里的execute调用的是BatchCommand确定的绘制函数,CUSTOM_COMMAND调用是传入的func函数,这里看一下BatchCommand的execute函数。
1 void BatchCommand::execute() 2 { 3 //设置渲染材质 4 //shader 5 _shader->use(); 6 //先取得MV和P,然后将MV和P相乘得到MVP,即模型视图投影矩阵 7 _shader->setUniformsForBuiltins(_mv); 8 //选择纹理单元,建立一个绑定到目标纹理的有名称的纹理 9 GL::bindTexture2D(_textureID);10 //混合11 GL::blendFunc(_blendType.src, _blendType.dst);12 //绘制13 _textureAtlas->drawQuads();14 } 首先介绍其中一个重要的概念MVP,MVP即模型(Model)、视图(View)、投影(Projection)。
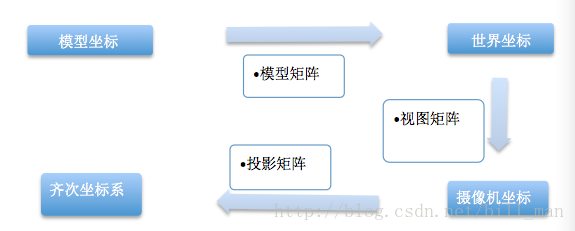
模型矩阵:所有物体都处于世界空间中,所以绘制和做变换的前提是把物体由模型空间转换到世界空间中,而这个转换就需要乘以模型矩阵。
视图矩阵:下一步需要把世界空间转换到相机空间或者是视角空间中,这需要乘以视图矩阵。
投影矩阵:最后需要将3d的立方体投影到一个2d平面上,需要从观察坐标系到齐次坐标系,需要乘以投影矩阵。整个过程如下图所示:
setUniformsForBuiltins函数
1 void GLProgram::setUniformsForBuiltins(const kmMat4 &matrixMV) 2 { 3 //通过flag中的变量判断是否使用了相关的矩阵,这些标志变量在updateUniforms被设置 4 kmMat4 matrixP; 5 6 kmGLGetMatrix(KM_GL_PROJECTION, &matrixP); 7 8 if(_flags.usesP) 9 setUniformLocationWithMatrix4fv(_uniforms[UNIFORM_P_MATRIX], matrixP.mat, 1);10 11 if(_flags.usesMV)12 setUniformLocationWithMatrix4fv(_uniforms[UNIFORM_MV_MATRIX], matrixMV.mat, 1);13 14 if(_flags.usesMVP) {15 kmMat4 matrixMVP;16 kmMat4Multiply(&matrixMVP, &matrixP, &matrixMV);17 setUniformLocationWithMatrix4fv(_uniforms[UNIFORM_MVP_MATRIX], matrixMVP.mat, 1);18 }19 20 if(_flags.usesTime) {21 Director *director = Director::getInstance();22 //这里不会使用真实的每帧时间去设置,那样太耗费效率23 float time = director->getTotalFrames() * director->getAnimationInterval();24 25 setUniformLocationWith4f(_uniforms[GLProgram::UNIFORM_TIME], time/10.0, time, time*2, time*4);26 setUniformLocationWith4f(_uniforms[GLProgram::UNIFORM_SIN_TIME], time/8.0, time/4.0, time/2.0, sinf(time));27 setUniformLocationWith4f(_uniforms[GLProgram::UNIFORM_COS_TIME], time/8.0, time/4.0, time/2.0, cosf(time));28 }29 30 if(_flags.usesRandom)31 setUniformLocationWith4f(_uniforms[GLProgram::UNIFORM_RANDOM01], CCRANDOM_0_1(), CCRANDOM_0_1(), CCRANDOM_0_1(), CCRANDOM_0_1());32 } 这个函数里,有一个频繁出现的变量名uniforms,uniform是一种和着色器相关的,它必须被声明为全局变量,用于整个图元批次向保持不变的着色器传递数据,对于顶点着色器来说,可能最普遍的统一值就是变换矩阵,它通过调用glUniformXXXX系列函数向着色器传递数据,这里这个函数被封装了,调用setUniformLocationXXXX系列函数可以设置uniforms,这个函数首先通过调用updateUniformLocation函数判断这个uniforms的值是否确实被更新(在一个hash表里存上曾经设置过的键值对),如果确实需要被更新再调用glUniformXXXX更新这个uniforms,节约效率
bindTexture2DN函数主要是调用glActiveTexture和glBindTexture做贴图的绑定
1 void bindTexture2DN(GLuint textureUnit, GLuint textureId) 2 { 3 #if CC_ENABLE_GL_STATE_CACHE 4 //做缓存,那么就不用为相同的textureId重复调用了 5 CCASSERT(textureUnit < kMaxActiveTexture, "textureUnit is too big"); 6 if (s_currentBoundTexture[textureUnit] != textureId) 7 { 8 s_currentBoundTexture[textureUnit] = textureId; 9 activeTexture(GL_TEXTURE0 + textureUnit);10 glBindTexture(GL_TEXTURE_2D, textureId);11 }12 #else13 14 glActiveTexture(GL_TEXTURE0 + textureUnit);15 glBindTexture(GL_TEXTURE_2D, textureId);16 #endif17 } glActiveTexture选择一个纹理单元,线面的纹理函数将作用于该纹理单元上,参数为符号常量GL_TEXTUREi ,i的取值范围为0~N-1,N是opengl实现支持的最大纹理单元数,这里,因为批处理只有一个纹理,所以textureUnit一直是0,由于使用缓存,只会被调用一次
glBindTexture建立一个绑定到目标纹理的有名称的纹理。比如把一个贴图绑定到一个形状上。
最后调用的绘制函数和上一篇介绍的类似,另外关于shader和混合的问题,将在后面单独开文章介绍
在引擎中使用BatchCommand这个命令的地方有两处ParticleBatchNode和SpriteBatchNode,使用方法很简单。
1 _batchCommand.init(2 _globalZOrder,3 _shaderProgram,4 _blendFunc,5 _textureAtlas,6 transform);7 renderer->addCommand(&_batchCommand);
需要说明的是,在3.0之后的版本中,由于添加了auto-batch功能,ParticleBatchNode和SpriteBatchNode的节约效率的功能已经不那么明显,但是3.0之前的版本中,把精灵放在SpriteBatchNode父节点上和将粒子系统放在ParticleBatchNode,是能够把相同的精灵批处理,对于相同的贴图只调用一次绘制函数,还是对提升效率很有帮助的。
如有错误,欢迎指出
下一篇介绍图形渲染